|
Auto encoders are one of the unsupervised deep learning models. The aim of an auto encoder is dimensionality reduction and feature discovery. An auto encoder is trained to predict its own input, but to prevent the model from learning the identity mapping, some constraints are applied to the hidden units.
The simplest form of an auto encoder is a feedforward neural network where the input 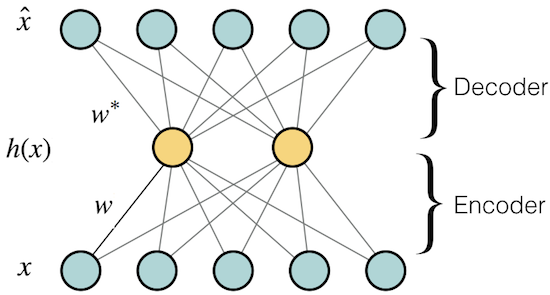
The following equation can describe an autoencoder: where The autoencoder tries to reconstruct the input. So if inputs are real values, the loss function can be computed as the following mean square error (MSE): where It can be shown that if a single layer linear autoencoder with no activation function is used, the subspace spanned by AE's weights is the same as PCA's subspace. PyTorch Experiments (Github link)Here is a link to a simple Autoencoder in PyTorch. MNIST is used as the dataset. The input is binarized and Binary Cross Entropy has been used as the loss function. The hidden layer contains 64 units. The Fig. 2 shows the reconstructions at 1st, 100th and 200th epochs: 
|
|
In a denoising auto encoder the goal is to create a more robust model to noise. The motivation is that the hidden layer should be able to capture high level representations and be robust to small changes in the input. The input of a DAE is noisy data but the target is the original data without noise:
Where PyTorch Experiments (Github link)
Here is a PyTorch implementation of a DAE. To train a DAE, we can simply add some random noise to the data and create corrupted inputs. In this case 20% noise has been added to the input. The Fig3 shows the input ( 

|
|
In a VAE, there is a strong assumption for the distribution that is learned in the hidden representation. The hidden representation is constrained to be a multivariate guassian. The motivation behind this is that we assume the hidden representation learns high level features and these features follow a very simple form of distribiution. Thus, we assume that each feature is a guassian distribiution and their combination which creates the hidden representation is a multivariate guassian. From a probabilistic graphical models prespective, an auto encoder can be seen as a directed graphical model where the hidden units are latent variables (
where
The posterior distribiution (
Now the likelihood is parameterized by In this setting, the following is a lower-bound on the log-likelihood of The second term is a reconstruction error which is approximated by sampling from 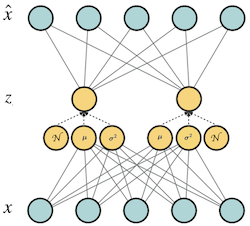
In shortA variational autoencoder has a very similar structure to an autoencoder except for several changes:
The Reparametrization Trick
The problem that might come to ones mind is that how the gradient flows through a VAE where it involves sampling from 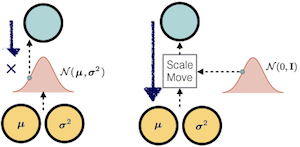
PyTorch Experiments (Github link)Here is a PyTorch implementation of a VAE. The code also generates new samples. It also does a generation with interpolation which means that it starts from one sample and moves towards another sample in the latent space and generates new samples by interpolating between the mean and the variance of the first and second sample. Fig7. shows the generated samples with interpolation. 
|